
Authors: Prof. Dr. Philipp Koellinger and Ogban Ugot
Zero hallucinated citations: SciWeave's ScholarQABench results
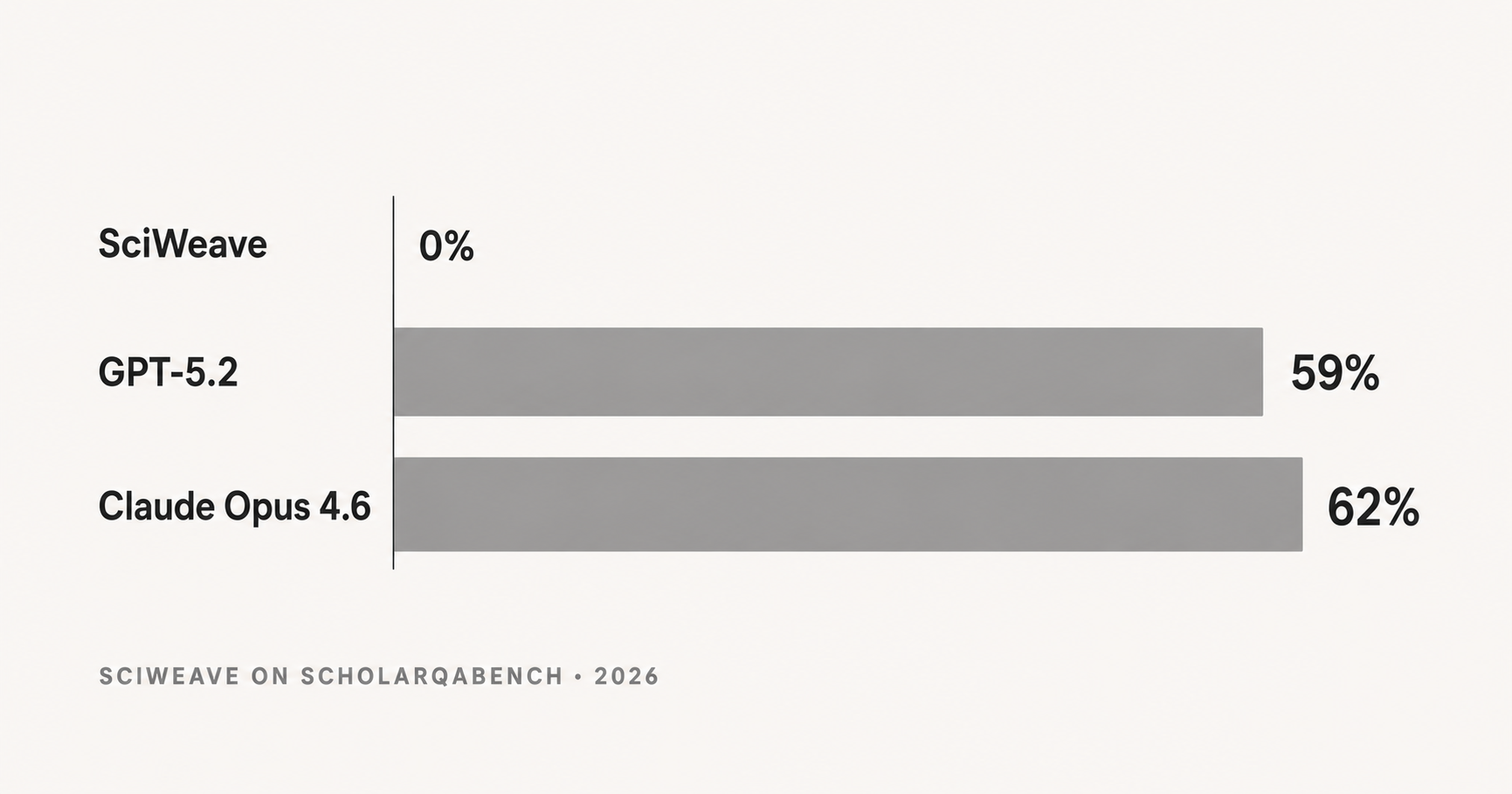
On a 100-query sample of ScholarQABench — the citation-grounded long-form scientific QA benchmark introduced by Asai et al. in Nature (2026) — SciWeave returned zero hallucinations out of thousands of referenced papers. GPT-5.2 hallucinated 59% of its cited papers. Claude Opus 4.6 hallucinated 62%. SciWeave also scored higher on citation recall and citation precision. Full methodology below; replication scripts on GitHub.
Hallucinated citations are a real problem
Fabricated citations from AI chatbots are not a theoretical risk. Wilder & Walters (2023) showed in Scientific Reports that ChatGPT invents bibliographic citations at high rates, and that even its real GPT-4 citations contain substantive errors in roughly 24% of cases [1]. Glynn (2025) documents fabricated citations that have already found their way into peer-reviewed bibliographies [2].
The contamination of published articles with AI-generated fake references can affect future work and undermine the integrity of the scientific corpus. When AI-assisted manuscripts cite invented sources, downstream papers cite those manuscripts, and errors compound. Manual verification does not scale to the volume of AI-assisted writing now reaching journals, and current AI-error detection tools are not accurate enough to plug the gap [3].
The benchmark: ScholarQABench
ScholarQABench is a citation-grounded long-form QA benchmark introduced as part of the OpenScholar work published in Nature by Asai et al. in 2026 [4]. It covers 1,451 biomedical questions and 1,308 neuroscience questions — 2,759 in total — each requiring a multi-sentence answer with inline citations. The accompanying scoring scripts evaluate three things: do the cited passages actually support the claims they're attached to (citation recall), are the cited passages necessary or just noise (citation precision), and how many of the cited papers exist at all (hallucination ratio).
The benchmark is exactly the right shape for testing a system like SciWeave. It evaluates the property that matters: not whether the AI says something that sounds plausible, but whether the evidence it points to actually exists and actually supports the claim.
How we ran the test
We drew 100 random queries from the combined Bio + Neuro corpus and ran three systems side by side:
- SciWeave — through our `api/answer-with-citations` endpoint, introductory answer complexity level (default).
- Chat GPT-5.2 — direct OpenAI API call, no retrieval tools.
- Claude Opus 4.6 — direct Anthropic API call, no retrieval tools.
GPT-5.2 and Claude were called as bare LLMs because that's how most researchers actually use them today: ask a question, get an answer. The comparison is "frontier LLM alone" versus "SciWeave's retrieval-augmented architecture."
Citation correctness was scored with the public ScholarQABench script `citation_correctness_eval.py` from the Asai et al. repository. It uses an attribution NLI judge (`osunlp/attrscore-flan-t5-xl`) that labels each cited passage as Attributable, Contradictory, or Extrapolatory. Only Attributable counts as support. The hallucination ratio is the share of cited papers that cannot be resolved against the reference index.
This is our benchmark run. The replication doc lets anyone reproduce it from raw scripts.
Try SciWeave on your own research question.
Results
Table 1: Combined results(biomedicine + neuroscience):
Table 2: Biomedicine
Table 3: Neuroscience
The 0% hallucination ratio for SciWeave holds across every subset we ran. SciWeave also cited more papers per answer (~10) than either competitor (3-7), and at higher recall and precision.
How SciWeave hits zero hallucinations
SciWeave does not ask the LLM to recall papers or write answers directly. Instead, it first retrieves the most relevant academic articles from OpenAlex — an open index of roughly 300 million scientific works — and in medical mode also queries ClinicalTrials and PubMed. The LLM then synthesizes the answer from the results of the most relevant peer-reviewed papers. Every citation it emits is a real document from the retrieval set, by construction. The 0% hallcuation ratio is the result of a system design in which fabrication is structurally precluded.
This architecture - retrieval-augmented generation, or RAG — is now the dominant approach in the LLM literature for grounding model output in external sources [5, 6]. Implementation matters: a retrieval system that returns weak or off-topic passages still produces ungrounded answers. SciWeave's index is curated to peer-reviewed scientific articles that pass a cascade of quality assurance and relevance bars, and the retrieval-and-rerank pipeline is tuned specifically for long-form research questions.
What this means for researchers
- Citations are real and verifiable. Your work can rely on them.
- Higher citation density. ~10 papers cited per answer versus ~4 for GPT-5.2 and ~7 for Claude Opus 4.6 — more relevant evidence surfaced per question, at the same researcher effort.
- Export straight to your reference manager. Every SciWeave answer exposes its cited references as .bib (BibTeX → LaTeX / Overleaf) or .ris (Zotero, Mendeley, EndNote, Papers). Citations can move from SciWeave into your reference manager without manual re-keying.
- Threads persist across sessions. A literature review does not have to live inside one continuous chat — you can resume a research thread days or weeks later with the citations intact.
- Build automated research workflows. Use the SciWeave MCP connection for Claude, ChatGPT, and other AIs to build exactly what you need, while grounding your work in the most relevant scientific references.
Get the SciWeave MCP and bring grounded research into your AI client
Replicate our results yourself
The ScholarQABench dataset, the citation scoring script, and the NLI judge model we used for our analyses are all publicly available. The replication doc lists, the exact commands, prerequisites, and expected outputs from our run can be found here: https://github.com/desci-labs/SciWeave/blob/main/SciWeave-ScholarQABench-Replication-Instructions.md. If you reproduce the numbers — or get different ones — we want to hear about it (info@desci.com)!
References
1. Wilder & Walters (2023). Fabrication and errors in the bibliographic citations generated by ChatGPT. Scientific Reports. (https://doi.org/10.1038/s41598-023-41032-5)
2. Glynn (2025). Guarding against AI-hallucinated citations: the case for full-text reference deposit. European Science Editing.(https://doi.org/10.3897/ese.2025.e153973)
3. Pellegrina & Helmy (2025). AI for scientific integrity: detecting ethical breaches, errors, and misconduct in manuscripts. Frontiers in AI. (https://doi.org/10.3389/frai.2025.1644098)
4. Asai, A., He, J., Shao, R., Shi, W., Singh, A., Chang, J., Lo, K., Soldaini, L., Feldman, S., D'Arcy, M., Wadden, D., Latzke, M., Sparks, J., Hwang, J., Kishore, V., Tian, M., Ji, P., Liu, S., Tong, H., Wu, B., Xiong, Y., Zettlemoyer, L., Neubig, G., Weld, D., Downey, D., Yih, W., Koh, P., & Hajishirzi, H. (2026). Synthesizing scientific literature with retrieval-augmented language models. Nature. (https://doi.org/10.1038/s41586-025-10072-4)
5. Gupta (2025). Retrieval-Augmented Generation and Hallucination in Large Language Models: A Scholarly Overview. Scholars Journal of Engineering and Technology. (https://doi.org/10.36347/sjet.2025.v13i05.003)
6. Zhao et al. (2025). Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. Computational Linguistics. (https://doi.org/10.1162/coli.a.16)

.svg)


.svg)
.svg)